Documenting AI Agent Code


It is Saturday night. You are finally watching that show everyone has been telling you about. Your phone buzzes. Production is down. The payment service is throwing 500 errors.
You open the code. You stare at it. You merged this three months ago. Your AI assistant generated it, the tests passed, the PR got approved, and you shipped it.
And now you are sitting there, on your couch, trying to reverse-engineer the thought process of a model that does not have thoughts.
Your partner looks over and asks if everything is okay.

You say you just need to debug code that nobody wrote.
That sentence should terrify you. And it is happening in codebases everywhere, right now. Coding agents accelerate delivery, but they create a massive documentation lag. Code gets merged faster than humans can contextualize it. The question is not whether to document agent-generated code. The question is how to do it without slowing down the team or creating a permanent backlog.
The Productivity Illusion
We are measuring the speedometer, but nobody is checking the engine.
Sprint velocity is up. PRs are merging faster. Test coverage is sitting pretty at 94 percent. Everything is green. Everything is humming. 84% of developers use or plan to use AI tools, and median PR throughput has risen despite a 65% increase in AI tool usage.
But it feels like everything takes longer to fix.
When a human writes a shortcut, they usually know it is a shortcut. They remember where it is. They can explain why they did it. The debt is visible, at least to the person who created it.
When an AI generates code, the shortcuts are invisible. The developer who merged it may not even recognize them as shortcuts. They look like clean, well-structured code. They pass every check. And they accumulate at the speed of AI generation, which is 10 to 50 times faster than human coding.
The time you spend debugging, maintaining, and trying to understand AI-generated code will eventually exceed the time the AI saved you in the first place. This is not a hypothetical. 88% of software developers report at least one negative impact of AI on technical debt.
The Three Invisible Debts
This invisible debt hides in three specific places.
First, comprehension debt. This is code that runs correctly, passes every test, ships to production without a single issue, and that nobody on your team can actually explain. It is the erosion of shared understanding across a software system over time.
When you used to write code yourself, you made decisions. You used a map because lookup speed mattered. You handled an edge case because you saw it in production last month. Every line had a reason, even if you did not write it down.
When AI generates code, the decisions are made for you. You went from being the author of your code to being the audience for it.
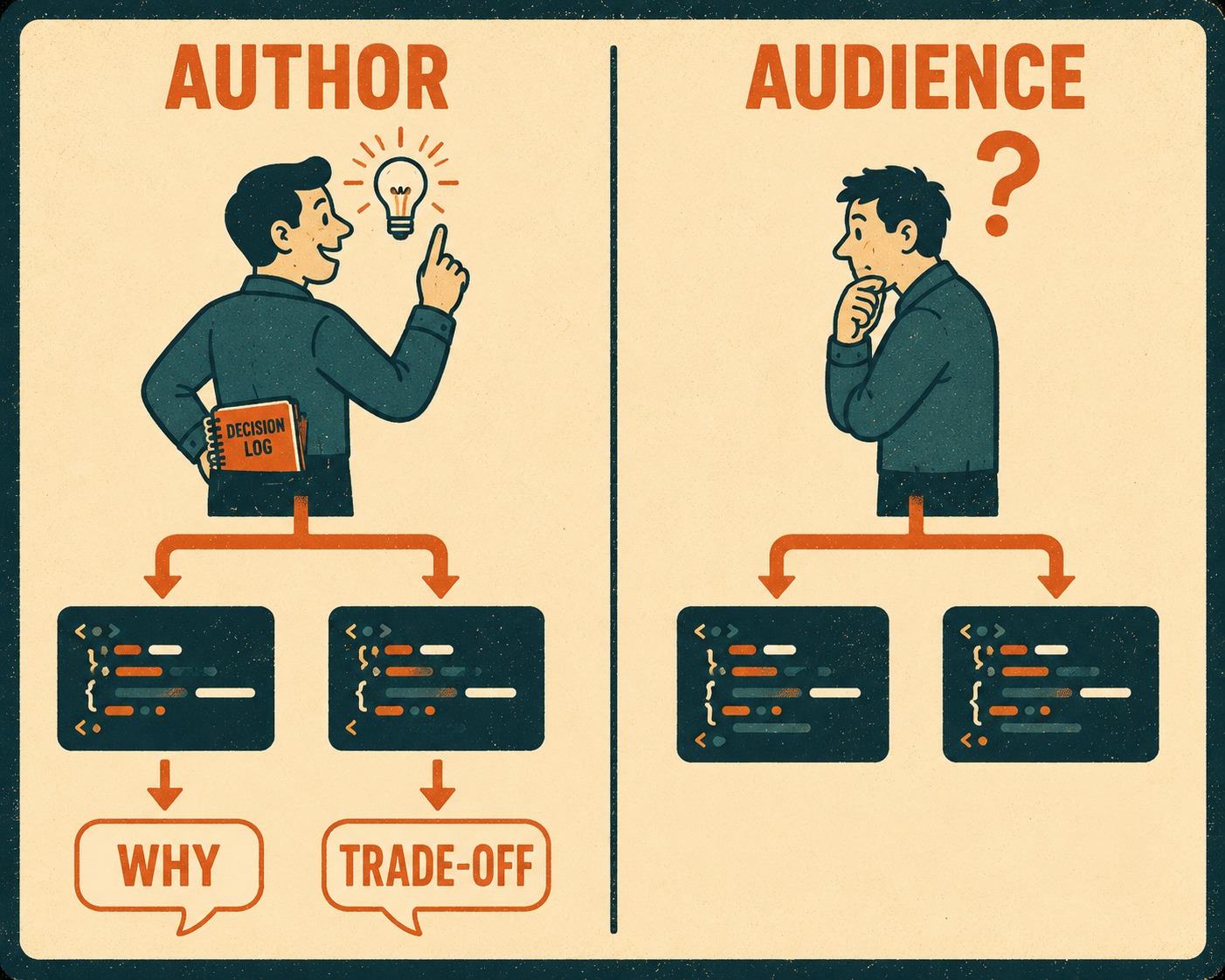
Second, homogeneity debt. This is when your entire codebase starts to look like it was written by one person.
Because it was. It was written by a model.
If two different teams use AI to generate a rate limiter, they will get basically the same code. The model learned the most popular pattern from thousands of repositories. It is battle-tested. It is fine.
But a senior developer who understands your specific traffic patterns, your specific infrastructure, and your specific failure modes might have written something completely different. The AI gives you the average of every solution it has ever seen.
Third, ownership debt. It is in your repo, but it is not your code.
When something breaks, the developer says they will try regenerating it with a different prompt.
That is not debugging. That is gambling.
The Shift to Intent
Treat agent-generated code like inherited legacy code.
It exists. It is in production. Reverse-engineering intent is now part of the job. The documentation process starts after the fact, not during development. Researchers are calling this intent debt: the absence of externalized rationale that developers need to work safely with code.
Not all agent code needs the same level of documentation. Code that touches critical paths, code that is likely to be modified by other engineers, code with non-obvious logic, code that interfaces with external systems: these deserve real attention. Straightforward CRUD operations (basic create, read, update, delete functions) and one-off scripts can wait.
The goal is not to document every function. The goal is to answer the questions a future engineer will actually ask. What does this module do? Why does it exist? What are the key constraints or assumptions? What breaks if you change X? A well-structured README or inline comment block at the module level often beats line-by-line comments.
The agent itself is a useful first-pass tool. Coding agents can generate docstrings, API references, and high-level summaries faster than humans. The output will not be perfect, but it is a starting point. The human role becomes validation and gap-filling: adding the context the agent could not infer because it does not know your business logic or deployment constraints.
If your team is merging agent PRs without a documentation check, you are accruing technical debt. Add a step before code goes to main. Validate that sufficient context exists for the next person who touches it. This does not mean formal docs for everything. Sometimes a comment block is enough.
The system level is where human engineers add the most value. Agent-generated microservices or API endpoints need integration context. How does this fit into the broader architecture? What upstream or downstream dependencies exist? What is the expected behavior under load? This is the connective tissue the agent does not see.
If your agents are generating similar solutions across multiple repos, document the pattern once and link to it. Turn "document every instance" into "document the template and note deviations."
How to Stop the Bleeding
Engineers often resist documentation because it feels like extra work that slows them down.
Reframe it. Undocumented agent code becomes a tax on every engineer who touches it later. Five minutes of context now saves thirty minutes of reverse-engineering next quarter. The team that documents agent output well ships faster over time because they are not constantly rediscovering what their own codebase does.
The tooling layer matters. Static analysis tools can flag undocumented functions or missing docstrings. Linters can enforce standards.
But the real unlock is automated documentation generation that pulls directly from the codebase and version control. Release notes, changelogs, and API references that regenerate as code changes.
This is where a system like Doc Holiday becomes relevant. It generates structured documentation from the engineering workflow itself, then provides a validation layer for a human to confirm accuracy and add the context the system cannot infer. A senior engineer or technical writer manages the output, ensures it aligns with actual system behavior, and fills in the "why" that agents and automation miss.
The result is documentation that scales with agent-assisted development, not against it. Teams using coding agents effectively are rethinking their documentation workflows, not abandoning them.


