How to Write a Post-Mortem Action Items Section That Gets Done

You're sitting in the post-mortem for an incident that took down the checkout service for forty-five minutes. The timeline is clean. The root cause analysis is blameless. The team is nodding. And then you get to the action items section.
There are eight of them. They say things like "improve monitoring coverage" and "update the runbook" and "investigate rate limiting." Everyone agrees they are good ideas. Everyone agrees they are necessary.
And everyone secretly knows that maybe one of them will actually happen.
The rest will go into a Jira backlog. They will sit there until Q3. Then Q4. Then the person who wrote the ticket will leave the company, and six months later, the checkout service will go down again for the exact same reason.

The problem isn't that your team is lazy or that your post-mortem culture is bad. Action items fail because they're written like feature requests, not like commitments with owners and constraints. If you want an action items section that actually gets done, you have to change how you write them.
Why They Rot in the Backlog
The typical action item is written in the final ten minutes of a post-mortem, when everyone is tired and wants to close the meeting. It gets phrased as a direction, not a destination. "Improve monitoring coverage" sounds like an action item. It has a verb. It names a thing. But it has no owner, no deadline, no definition of done, and no mechanism to surface whether it happened.
That's not a commitment. That's a note to self, written by a committee, addressed to no one.
The research on software incident management has long pointed to the same gap: post-mortems are good at diagnosing failure and poor at driving follow-through. Google's SRE team identified this as a distinct problem worth addressing separately from post-mortem culture itself, noting that designing a good action item plan and then executing it are two different skills.The diagnosis part is collaborative and energizing. The follow-through part is unglamorous, and it competes with everything else on the team's plate the moment the meeting ends.
The Four Non-Negotiable Elements
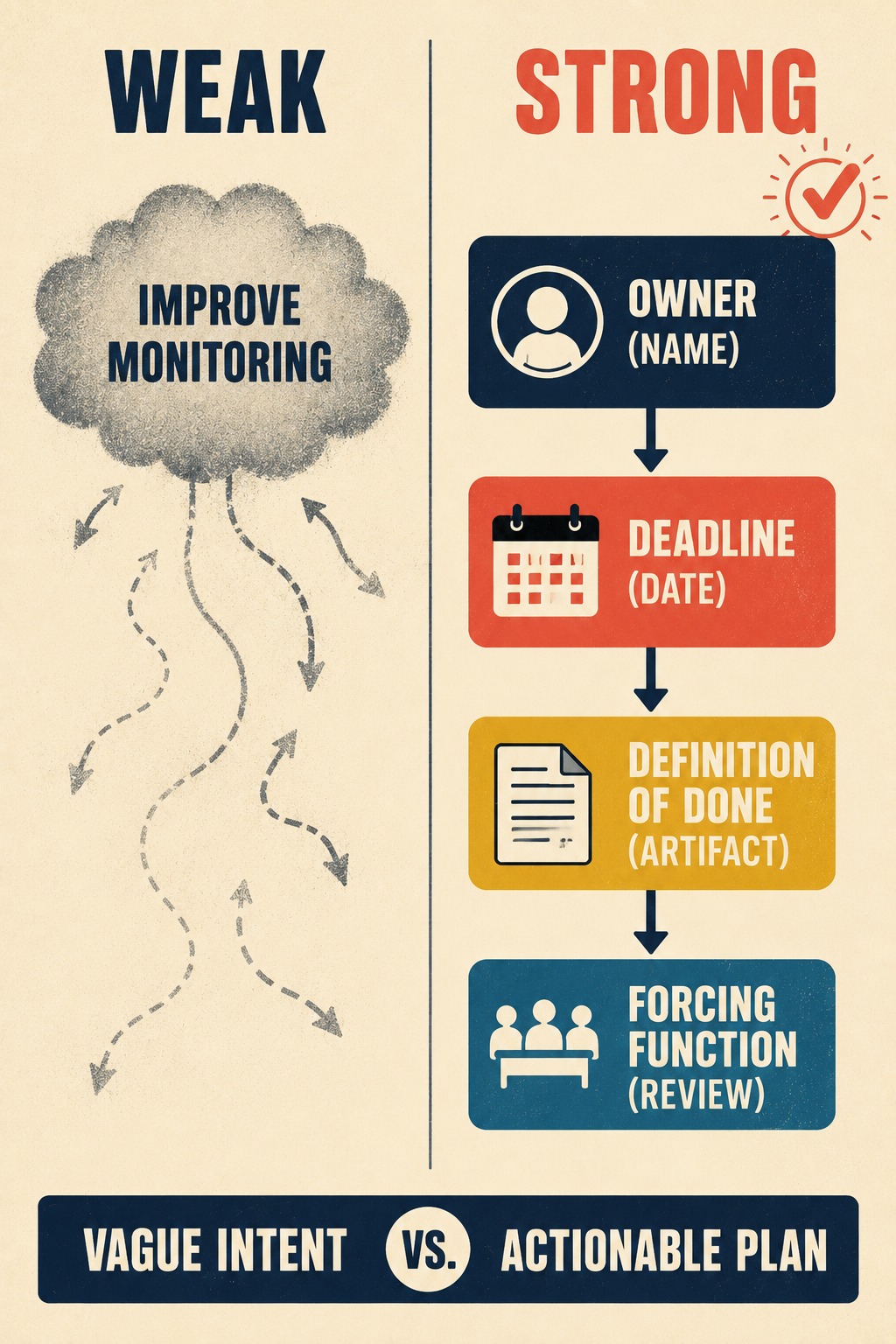
A real action item has four parts. If it's missing any of them, it's a wish.
The first is a specific owner. Not a team. Not a pod. A name. "The SRE team" cannot own an action item, because "the SRE team" cannot feel the mild, specific panic of a deadline approaching. A person can.
The second is a deadline that reflects actual priority. "Q3" is not a deadline. "March 15" is a deadline. The difference matters more than it sounds, because "Q3" gives everyone permission to defer indefinitely while technically not being late.
The third is an explicit definition of done. What artifact or state marks completion? "Improve monitoring" is a direction. "Add CPU threshold alerts to the checkout service" is a destination. You need to be able to answer, unambiguously, whether the item is done or not done.
The fourth is a forcing function: a review, a handoff step, or a check-in that will surface whether the item was completed. Without this, the item can quietly expire without anyone noticing.
The difference between a weak and a strong action item is stark:
Triage in the Room, Not Later
Teams skip action items because priorities shift, or the work turns out to be harder than estimated. That's reality. You have to handle it in the room, not after the fact.
Triage the items immediately. P0 means it must happen. P1 means it should happen. P2 means it would be nice. Only commit to P0 items as non-negotiable. Let the P1 and P2 items compete in the normal backlog. If they don't get done, they don't get done, and that's an acceptable outcome you've already accounted for. The incident.io team puts it plainly: closing a post-mortem should be a conscious act, where every action is either completed or explicitly deprioritized with a documented reason. Passive drift into nothing is the default if you don't actively prevent it.
The harder discipline is sizing. Make P0 items small enough to finish in two weeks. If a P0 item cannot be done in two weeks, it is not an action item. It is a project, and it needs a project plan with a sponsor, a timeline, and a milestone structure. Calling it an action item doesn't make it one; it just makes it a project that will fail quietly.
This is also where the post-mortem owner earns their role. Someone needs to be explicitly responsible for tracking action items to completion, not doing the work, but closing the loop. This is usually the incident commander or the on-call lead. Their job is narrow: send one follow-up message three days before each deadline, and escalate anything that's blocked. If no one owns follow-through, nothing happens. That's not a culture problem; it's a missing role.
Forcing Functions That Actually Work
The best accountability mechanisms are the ones that don't require anyone to remember to use them.
Review action items in the weekly engineering sync. Five minutes. Just status. Done or not done. This works because it's low overhead and it makes the status visible to the whole team, which is a mild but real form of social accountability.
A more aggressive option: make incomplete P0 items from previous post-mortems block closing new post-mortems. You cannot move on until you finish what you committed to last time. Some teams resist this because it feels punitive, but it's actually clarifying. It forces a real conversation about whether the P0 designation was accurate in the first place.
The lightest-weight option is a single step in the on-call runbook: before handoff, check for open action items. This takes thirty seconds and ensures that at least one person per rotation looks at the list.
When to Write Fewer of Them
Two well-scoped P0 items that actually get done are worth more than ten aspirational items.
If the post-mortem surfaces eight things that should improve, write two as action items. Capture the rest as backlog tickets labeled "tech debt — post-mortem." This keeps the action items section credible. When there are only two, and they are both P0, people know you mean it. When there are eight, people know you're being optimistic.
The credibility of the action items section is a resource. Every time items rot in the backlog, you spend a little of it. Eventually, the section becomes a ritual that everyone participates in without believing in, and then you have a culture problem on top of an execution problem.
The Documentation Trap
The most common failed action item is "update the runbook" or "document the workaround."
These fail because writing good documentation is hard. It takes longer than expected. It competes with feature work, and documentation always loses, because documentation doesn't have a sprint ticket, a product manager, or a deadline tied to a customer commitment.
The fix is to lower the bar to something that actually gets done. Instead of assigning "document the fix," assign "add a 3-sentence note to the runbook and link to this post-mortem." That's a fifteen-minute task. It can be done before the on-call handoff. You can improve it later if you need to; the important thing is that the next person on call has something to find.
When action items include "update API docs to reflect new error codes" or "add troubleshooting steps to the runbook," they get deprioritized because they feel like overhead. That's a structural problem, not a motivation problem. When documentation is generated as a byproduct of the engineering workflow (with structured content surfaced automatically by Doc Holiday and reviewed by the team), the action item stops being a burden. It just gets done.


