How to Document a Partial Outage Vs a Full Outage Differently


It is 2:00 PM on a Tuesday. You are staring at a Slack thread where your support team is getting hammered with confused tickets. Your monitoring dashboard shows a 5% error rate on the checkout API.
The engineers are arguing about whether this is a SEV-1 or a SEV-2. The support director is asking what to tell customers. You just need to figure out what to put on the status page.
This is the reality of the partial outage. It is fundamentally harder to communicate than a full outage because the impact is ambiguous. Customers experience inconsistent behavior. They blame their own internet connection or their own setup. They cannot tell if the problem is on their end or yours.
When the entire system is down, everyone knows it. The documentation job is simply explanation and an estimated time to recovery. But when only 5% of requests are failing, the documentation job is triage.
Treating these two scenarios the same is a mistake. Understating a full outage destroys trust. Overstating a partial outage creates alarm fatigue. And using vague language about "some users" makes everyone assume they are affected.
You need a different approach for each.
The Problem with a 5% Failure Rate
Partial outages create a specific kind of chaos.
When a service is completely down, support gets a spike of tickets, but those tickets are uniform. When a service is partially degraded, support gets a flood of confused, contradictory tickets. Some users can log in but cannot check out. Some users can check out but cannot see their history. None of them know whether to wait or call for help.
This confusion bleeds into the engineering response. If 8% of requests are failing, is that a critical emergency or a high-priority bug? Teams waste precious minutes debating severity classification instead of fixing the problem, a dynamic that PagerDuty's incident severity framework addresses by recommending teams declare the higher severity when in doubt and downgrade later. That rule only works, though, if the team agrees on what "higher" means for a partial failure.

The documentation risk here is significant. If you use vague language, you force your customers to self-diagnose. If you say "some users may experience issues," every user who reads that will assume their current problem is your fault. Support tickets spike. Engineers get pulled into customer calls. The blast radius of the communication failure grows larger than the blast radius of the actual incident.
Why Your Templates Are Failing You
Most companies use the same incident template for both partial and full outages. This breaks down quickly.
Templates are typically optimized for legal safety and completeness, not communication clarity. They want you to fill in the blanks. But a good partial outage report requires conditional logic that most static templates do not support, as Atlassian's incident communication template library illustrates by treating partial and full outages as distinct template types with different required fields.
You do not necessarily need separate templates. You need conditional sections. An "Affected scope" field that is mandatory for partial outages. A "Full service restoration timeline" that only appears for total outages. Different severity thresholds that map to different communication cadences. If your template forces you to write "All systems are down" when only the reporting dashboard is lagging, your template is broken.
The deeper problem is that templates optimize for the worst case. They assume a full outage because that is the scenario that generates the most legal and reputational risk. Partial outages, which are statistically more common, get squeezed into a format that was not designed for them.
When It's Only Broken for Some People
Partial outage documentation requires specific information that simply does not matter in a full outage.
You must define the exact affected scope. Name the specific regions, customer segments, feature sets, or workflows that are broken. "US-East API gateway for enterprise accounts created after January 2025" is useful. "Some users" is not.
You also need clear negative scope. Tell the customer what still works. If the reporting dashboard is down but data collection is still happening in the background, say that explicitly. If there is a workaround available, provide it immediately. Customers who know what still works can often continue their core workflows while you fix the broken part.
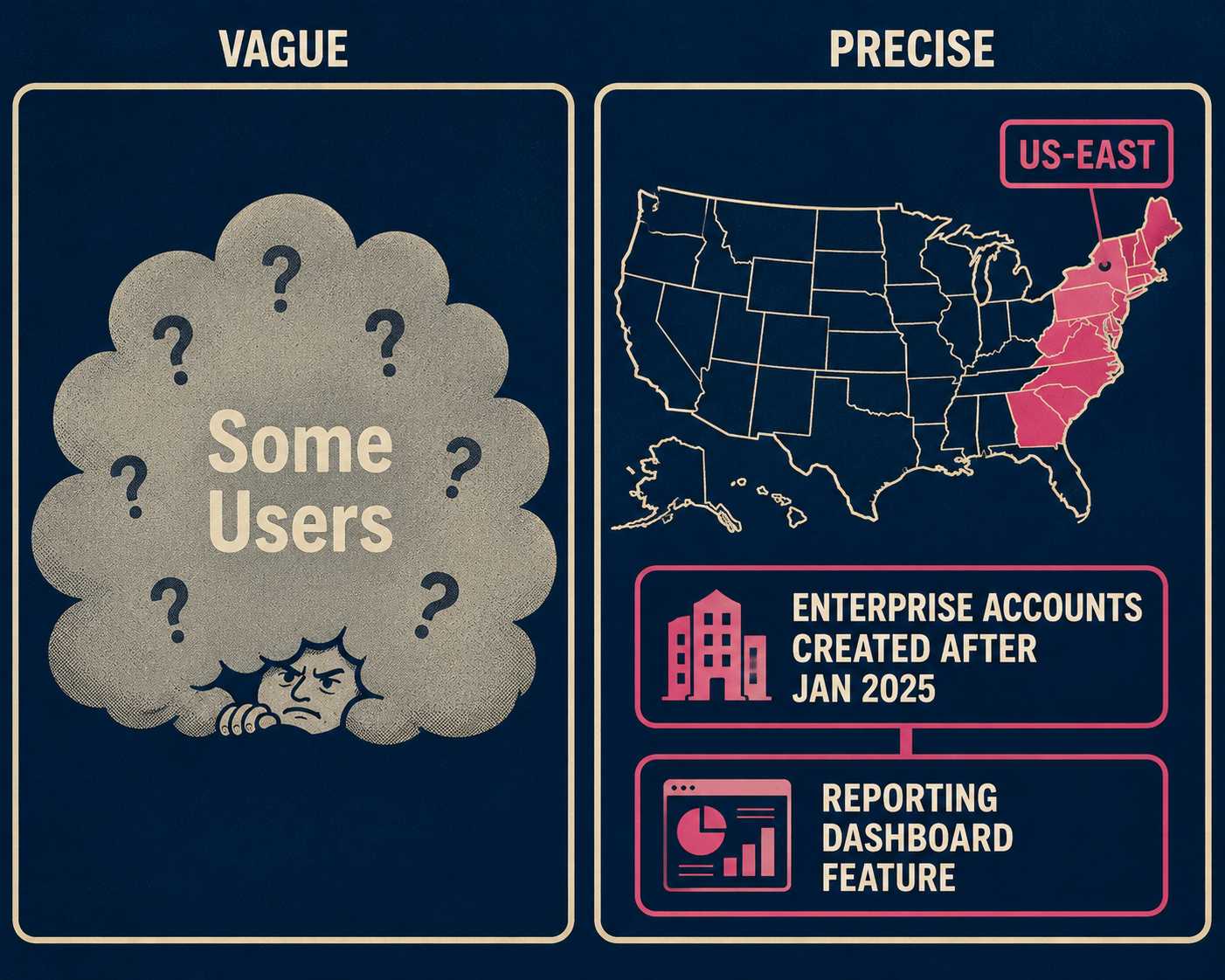
Communicating uncertainty without sounding evasive is the hardest part. The key is to be specific about what you know and what you are still investigating. Give a firm timeframe for the next update. Avoid the passive construction "some users may experience issues." Instead, say exactly which users and which issues. "Enterprise accounts in US-East cannot access the reporting dashboard. All other features are unaffected. We will provide an update by 3:30 PM ET" is a complete sentence. "We are investigating reports of degraded performance" is a placeholder.
When the Whole Thing Is Actually Down
Full outages are terrifying to experience, but they are conceptually simpler to document.
You can assume things about your audience that you cannot assume in a partial outage. Everyone knows the system is broken. No one is confused about the scope. They just want to know when it will be fixed.
The timeline section differs significantly. Partial outages need granular status updates as the scope changes and the blast radius shifts. Full outages need clear recovery checkpoints. "We have identified the root cause and are restoring from the most recent backup. Estimated recovery by 4:00 PM ET" is the full outage version of useful. It does not need to explain which users are affected because the answer is all of them.
The level of technical detail should also shift. Partial outages often require more specificity to help customers self-identify the impact. Full outages can usually remain higher-level. If the entire database cluster failed, the customer does not need to know the specific replication error until the post-mortem. They need to know you are restoring from backups and when they can expect service to resume.
What You Say Now vs What You Say Later
The style of your documentation must change depending on whether you are writing a live status page update or a post-incident report.
During the incident, speed and clarity are the only things that matter. For a partial outage, the live status page needs absolute scope clarity. For a full outage, it needs ETA clarity. Both need a committed time for the next update, even if that update is just "we are still working on it." Atlassian's incident communication guidance is direct on this point: silence makes customers assume you have forgotten about them.
After the incident, the post-mortem serves a different purpose. It is a factual artifact that should be free from personal judgments and subjective language, a principle that Google's SRE workbook on postmortem culture treats as foundational to blameless review. The post-mortem for a partial outage needs a detailed explanation of why the blast radius was limited. How did your architecture prevent the failure from cascading? What monitoring caught it? The post-mortem for a full outage needs a clear explanation of why the blast radius was not limited. Why did the failover not work? What assumption turned out to be wrong?
These are different questions. They require different sections. A template that treats them identically will produce a post-mortem that answers neither well.
Getting Engineers to Actually Write This Down
Generating accurate outage documentation while your engineers are busy fixing the problem is the hardest part of incident management.
If your documentation process requires an engineer to stop debugging, open a document, and write prose, it will not happen during a live incident. They will prioritize the fix over the communication. This is not a discipline problem. It is a workflow design problem.
The best outage documentation is not written from scratch. It is generated from the same internal tracking systems that engineers are already updating. Ticket statuses, Slack threads, commit messages, deployment logs. These artifacts already contain the information your customers need. The gap is translation, not collection.
Good tooling separates the content generation from the editorial review. Engineers should not be writing customer-facing copy while they are debugging. Support leads should not be guessing at technical root causes while they are managing the ticket queue. The two jobs require different information and different skills, and conflating them under pressure is how you end up with a status page that says "We are experiencing degraded performance" for four hours while customers churn — a pattern that PagerDuty's research on the cost of downtime traces directly to the absence of automated communication workflows.
Doc Holiday generates status page updates and incident reports directly from the engineering workflow, pulling from tickets, deploy logs, and commit history, then provides a structured validation step so a technical writer or support lead can review the output, adjust the scope language, and publish. It is built for teams that need accurate outage communication without pulling engineers off the fix.


